PL / SQL 이란 (Oracle's) Procedural Language extension to SQL 의 약자이다.
즉, 오라클에 내장되어 있는 프로그래밍 언어를 뜻한다.
쿼리문은 DB 를 사용하는 일종의 명령어이지만 PL / SQL 은 변수를 선언하는 등 좀 더 언어에 가까운 모습이다.
PL / SQL은 절차지향적 언어의 성격을 띄며 조건문(IF), 반복문(LOOP) 등을 처리할 수 있다.
이번 포스팅에서는 PL / SQL 에 대해 많은 내용을 다루진 못하며 어떤 개념인가에 대해 정리하고자 한다.
하지만 다음 포스팅 주제인 프로시저, 함수, 트리거와 관련하여 계속 사용되므로 꼭 읽어보도록 하자.
1. PL / SQL 의 예약어
PL / SQL을 사용하기 위해서는 다음과 같이 핵심적인 예약어들이 필요하다.
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
- 3행 선택3행 다음에 행 추가
|
DECLARE
|
변수선언
|
|
BEGIN
|
변수의 값 정의 및 SQL 문 작성 및 실행부
|
|
END
|
실행부의 끝
|
|
SET SERVEROUTPUT ON
|
화면에 결과 출력을 위한 시작 명령어
|
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
2. PL / SQL 사용하기
아래는 PL / SQL 을 사용한 코드이다.
SET SERVEROUTPUT ON
DECLARE
v_num number; -- 변수 선언
v_char char(5);
begin
v_num := 10; -- := 대입 연산자
v_char := 'HONG';
dbms_output.put_line(v_num); -- println 과 동일한 출력기능
dbms_output.put_line(v_char);
end;
/DECLARE 아래를 보면 V_NUM 이라는 NUMBER형의 변수를 선언하였다.
BEGIN 에서는 변수에 값을 대입한 것을 확인할 수 있는데 이 때 사용한 연산자( := ) 는 대입 연산자라는 점을 알아 두자.
밑에서 DBMS_OUTPUT.PU_LINE( ) 은 출력하기 위해 사용하는 함수로 자바의 println() 과 동일한 기능을 한다.
끝으로 end 를 통해 PL / SQL 이 끝남을 알린다. 또한 마지막에 / 를 사용하여 PL / SQL 의 한 블록이 끝났음을 뜻한다.

실행 결과
2. PL / SQL 과 SELECT 를 함께 사용하기.
위의 예제는 PL / SQL 을 사용하는 방법이였다. 이번에는 조금 응용하여 SELECT 문과 함께 사용하는 방법을 보자.
SELECT 문을 함께 사용하면 테이블에서 값을 가져와 변수에 대입하는 작업이 가능하다.
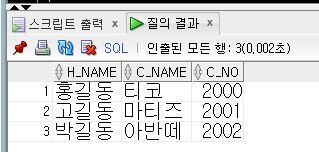
아래의 코드는 지난 예제로 사용했던 사람, 자동차 테이블을 사용하였다.
SET SERVEROUTPUT ON
DECLARE
V_H_NO number;
V_H_AGE HUMAN.H_AGE % TYPE; -- 지정한 컬럼과 같은 타입의 변수를 만듬.
BEGIN
SELECT H_AGE INTO V_H_AGE
FROM HUMAN
WHERE H_NAME = '고길동';
dbms_output.put_line(V_H_AGE);
end;
/BEGIN 을 보면 SELECT 구문이 들어간 것을 볼 수 있는데, 풀어서 써 보면 다음과 같다.
"HUMAN 테이블에서 H_NAME 이 '고길동' 인 사람의 H_AGE의 값을 V_H_AGE 에 넣고 출력해 주세요."
정도로 얘기할 수 있다. 따라서 실행 결과는 고길동의 나이가 출력될 것이다.

실행 결과
※ V_H_AGE HUMAN.H_AGE % TYPE; 구문의 뜻은
"V_H_AGE 라는 변수의 자료형은 HUMAN 테이블의 H_AGE의 자료형과 같습니다." 이다.
'DB > 구자료' 카테고리의 다른 글
| 저장 함수 (FUNCTION) (0) | 2022.08.28 |
|---|---|
| SQL 프로시저 (0) | 2022.08.28 |
| INDEX (0) | 2022.08.28 |
| VIEW (feat. OR REPLACE) (0) | 2022.08.28 |
| 시퀀스 (SEQUENCE) (0) | 2022.08.28 |